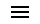

不认识冰箱就不能买火车票,12306的验证码为啥如此奇葩?
不认识冰箱就不能买火车票,12306的验证码为啥如此奇葩?

文末视频彩蛋,建议阅读文字后再观看你一定有过这样的经历,在12306上买火车票时,需要输入复杂且奇葩的验证码。如下图,需要点击图中所有的冰箱,然后才能登陆12306系统买票。
What,不认识冰箱就不让能火车票?当然不是,这一切都是因为网络爬虫。
想象一下,如果你的电脑屏幕上有数万、数百万只蜘蛛密密麻麻的爬行,是不是觉得很恐怖,如果你有密集恐惧症,甚至会感到很恶心。网络爬虫正是这样一种存在,只不过网络爬虫并不是真正的实物,而是一段你看不见的计算机程序。
那么,什么是网络爬虫呢?让我们先来看看相对书面一点的解释。
人们上网的基本原理是通过浏览器向服务器发出请求,服务器获得请求后将相关数据反馈给浏览器,浏览器进行渲染,然后展现在你的电脑屏幕上。网络爬虫就是按照一定的规则,自动地、快速地向服务器发起请求,抓取网络信息的程序,其主要作用就是请求目标网页,下载目标网页,解析目标网页并提取需要的数据。
What?还能不能说人话,说话的方式简单点!!!

好吧,再简单点说,你上网能做什么,爬虫就可以做什么。你能淘宝,爬虫也能淘宝;你能买火车票,爬虫也可以买火车票;你能下载电影,爬虫也能下载电影。但不同的是,它比你快,有多快,飞快!!!额...,So... 和我有什么关系!!!

事实上,爬虫关系到每一个人。而且,你每天都在接触爬虫。爬虫的作用很多,起码你可以用来抢月饼!
下面让我们来看一些生活中比较常见的爬虫应用场景,或许你就能基本明白什么是爬虫。
疯狂的抢票软件
如果你在北上广深,每当春运来临,你不得不面临一个问题,抢票。如果你想通过登录12306买票,那么能不能回家过年就只能靠运气了。因为与你一起抢票的并不是蹲守在电脑旁不断按着F5刷新余票的人,而是一个个抢票软件,而这些抢票软件本质上就是一段爬虫程序。程序通过频繁的、极其快速的访问12306网站,并解析网页中余票数据,一旦监测到余票数据大于零,立即添加购买。那么问题来了,你一秒钟可以刷新几次网页呢!因此,当你在吐槽12306的奇葩验证码时,请记住,12306是一个伟大的网站,尤其是在春运期间,它需要承受来自数亿人,以及众多爬虫程序在短时间内的高并发访问。
奇葩的12306验证码
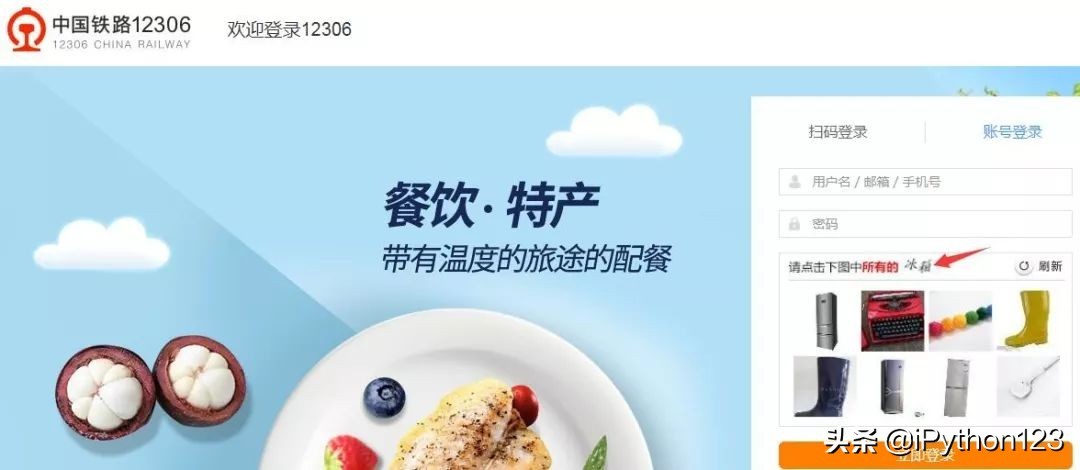
说完了抢票软件,我们再来说奇葩的验证码。你有么有想过,到底网站登录为什么要输入验证码呢?如下左图,为什么要多此一举输入一个8818呢?
由于爬虫能比人类正常行为更加快速的向服务器发生请求,给服务器带来很大压力,而且这些由程序发生的请求并不会给企业带来价值,因此,企业会制定反爬虫措施。验证码就是一种反爬虫的基本方法。因此,验证码的作用主要有两个,验证你是不是人,验证你是不是本人(手机验证码)。如果爬虫程序无法识别出验证码,就无法登陆。而简单的验证码,如上图中的验证码8818很容易可以通过图像识别技术识别出来。因此,12306不得不想出更复杂的验证码来反爬虫。这下你应该能理解12306复杂验证码的良苦用心了,没办法,爬虫太凶猛,反爬很难。当然,正所谓道高一尺魔高一丈,有爬虫的方法,就有反爬虫的措施,有反爬虫的措施就有反反爬虫的手段。顺便说一句,验证码(CAPTCHA)的全称是全自动区分计算机和人类的图灵测试。
薅羊毛(一场月饼引发的血案)
2016年,阿里巴巴内部展开的中秋抢月饼活动中,4名程序员使用js写了一段爬虫脚本来抢月饼,大致是当网页按钮变成了秒杀就狂点击,与12306抢票类似,结果多刷了124盒月饼,随即被阿里开除。 如今,每个电商平台都有很多促销活动,秒杀、优惠券、打折等让人眼花缭乱,同样的商品,到底哪个电商平台的价格实惠。当然,你可以一个一个网站进行对比,或者找一个比价网站,如返利网,折多多看看。那么这些比价网站是如何在几分钟之内甚至几秒钟的时间内就知道一件商品在某网站有优惠呢,其实就是一个数据采集系统(本质是爬虫)在实时监控各站的价格浮动。
刷评论(还有什么是真的)
正如现在给你打诈骗电话的并不一定是真人,而是机器人;与你微信聊天的并不是美女,而是抠脚大汉;网络评论也早已不需要一个一个人工刷评了。
2018年10月,一篇名为《估值175亿的旅游独角兽,是僵尸和水军构成的鬼城?》的文章引发热议。文章讲述了估值175亿的某旅游攻略,自由行,自助游分享社区上的2100万“真实点评”竟有1800万条是假的,而这些虚假点评很多抄袭至大众点评。简单的说,该公司将大众点评的用户评论复制粘贴到自己公司的社区上,而这1800万条评论当然不是人工复制粘贴,全部由爬虫程序执行。
搜索引擎(原来如此)
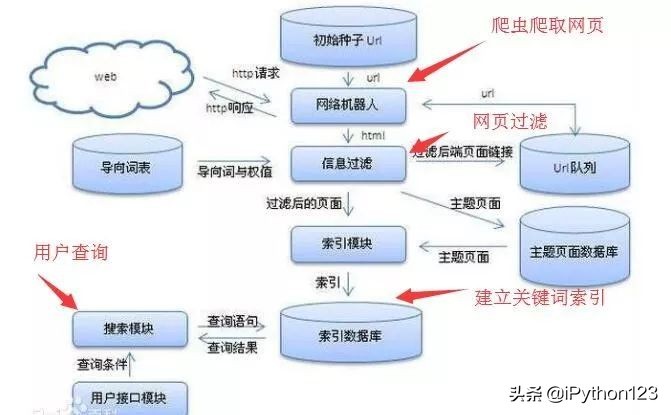
你每天都在使用百度、Google这些搜索引擎。百度甚至扬言“百度一下你就知道”,那么百度为什么知道这么多呢,当你在搜索引擎的搜索框中输入某个关键词时,到底发生了什么了。事实上,搜索引擎的工作原理基本可以分为四步:从万维网上爬虫网页、筛选网页、建立索引库、用户检索。
当然,爬虫的应用远不止于此,数据分析、舆情监控等等。总之,爬虫无处不在。
Python与爬虫
为什么很多时候我们会看到Python和爬虫经常一起出现,似乎爬虫就要用python编写呢。事实上,爬虫并不是Python的专利,Java、Js、C、PHP、Shell、Ruby等语言都可以实现,那为什么Python爬虫会这么火?最重要的原因就是Python爬虫简单!你可以借助requests、urllib、beautifulsoup等库或者srapy框架快速实现爬虫。
Tips:爬虫不仅仅增加了企业服务器的负担,而且数据是企业重要的资产,如果用户商业目的,可能违反国家法律,类似由于爬虫被判刑的案例不在少数。如,2019年3月,李开复投资的“巧达科技”因非法爬取用户简历数据2.2亿条,公司200多名员工被警方带走,后包括高管在内的36人被捕。
爬虫有风险 爬取需谨慎
彩蛋
为了便于大家更加形象的理解什么是爬虫,我用一款爬虫软件,爬取20条京东商城华为P30手机的用户评论数据。你将可以看到爬虫运行的整个过程,当然,一般情况下,自己编写的爬虫代码是不需要看到执行过程的。
点击查看其他文章Python安装超级详解丨免费获取一键安装包Python的前世今生,你必须知道的这10个方面!尼罗河的故事丨Python与高等数学之Python与积分庆国庆,晒国旗!Pythoneers,这才是你的正确方式!

-

- 德云社十大人气排名,于谦竟无缘前三,秦霄贤一炮而红
-
2025-09-21 16:21:09
-

- 43岁倪虹洁官宣新男友!曾隐婚生子,帮前夫还千万巨债
-
2025-09-21 16:18:54
-

- 已证实!动车组列车禁止车上办理延长补票!出站补票额外加收50%票款!能挡住
-
2025-09-21 16:16:39
-

- 回顾火星距离地球2亿公里,宇航员如果要上火星,需要多长时间?
-
2025-09-21 16:14:24
-

- 100 个福字,每一岁都有。
-
2025-09-20 23:36:59
-

- 10月1日起,“磁共振扫描”等30个医学影像检查项目,价格将下调
-
2025-09-20 23:34:44
-

- 张卫健张茜分居3年陷私生女风波,携神秘母女游船被拍,本尊回应
-
2025-09-20 23:32:29
-

- 田园东方践行“田园综合体”理念10年,运营40余个乡村振兴项目
-
2025-09-20 23:30:14
-

- 李雨桐:与薛之谦纠缠7年,分手后当怨妇,新恋情公布1年生女
-
2025-09-20 23:27:58
-

- 云南竟然有这么多机场!你的家乡有了吗?
-
2025-09-20 23:25:44
-

- 男跳水员的难言之隐:赛前刮毛是基础要求,泳裤太小容易被关注!
-
2025-09-20 23:23:28
-

- 邓咏诗虽然赌王已经去世但他给我的上亿分手费根本花不完
-
2025-09-20 23:21:13
-

- 著名歌手韩磊:三十多娶小14岁娇妻曾经的师妹,结婚十几年零绯闻
-
2025-09-20 23:18:58
-

- 血海深仇!张扣扣案:13年前的悲剧命运轮回。替母报仇被称大英雄
-
2025-09-20 23:16:43
-
- 河南省最牛的高中都在哪里?河南各地高中教育排名前十的都有谁?
-
2025-09-20 23:14:28
-
- 除了支付宝,这10款阿里出品的神器,每一款都直呼好家伙
-
2025-09-20 23:12:13
-

- 北大女博士娄滔,患渐冻症后捐器官,遗言令人泪目:当我从未来过
-
2025-09-20 23:09:57
-

- 精灵宝可梦24部剧场版大盘点,一次看个过瘾!
-
2025-09-20 06:34:27
-

- 经典影视里的迪士尼公主真人版&王室公主,你最喜欢哪一位?
-
2025-09-20 06:32:12
-

- 东北第一“神兽”傻狍子,到底有多傻傻到这份上都没灭绝
-
2025-09-20 06:29:57
 苍月奥特曼:来自宇宙的战士
苍月奥特曼:来自宇宙的战士 字节跳动市值多少亿(字节跳动高估值的原因)
字节跳动市值多少亿(字节跳动高估值的原因)